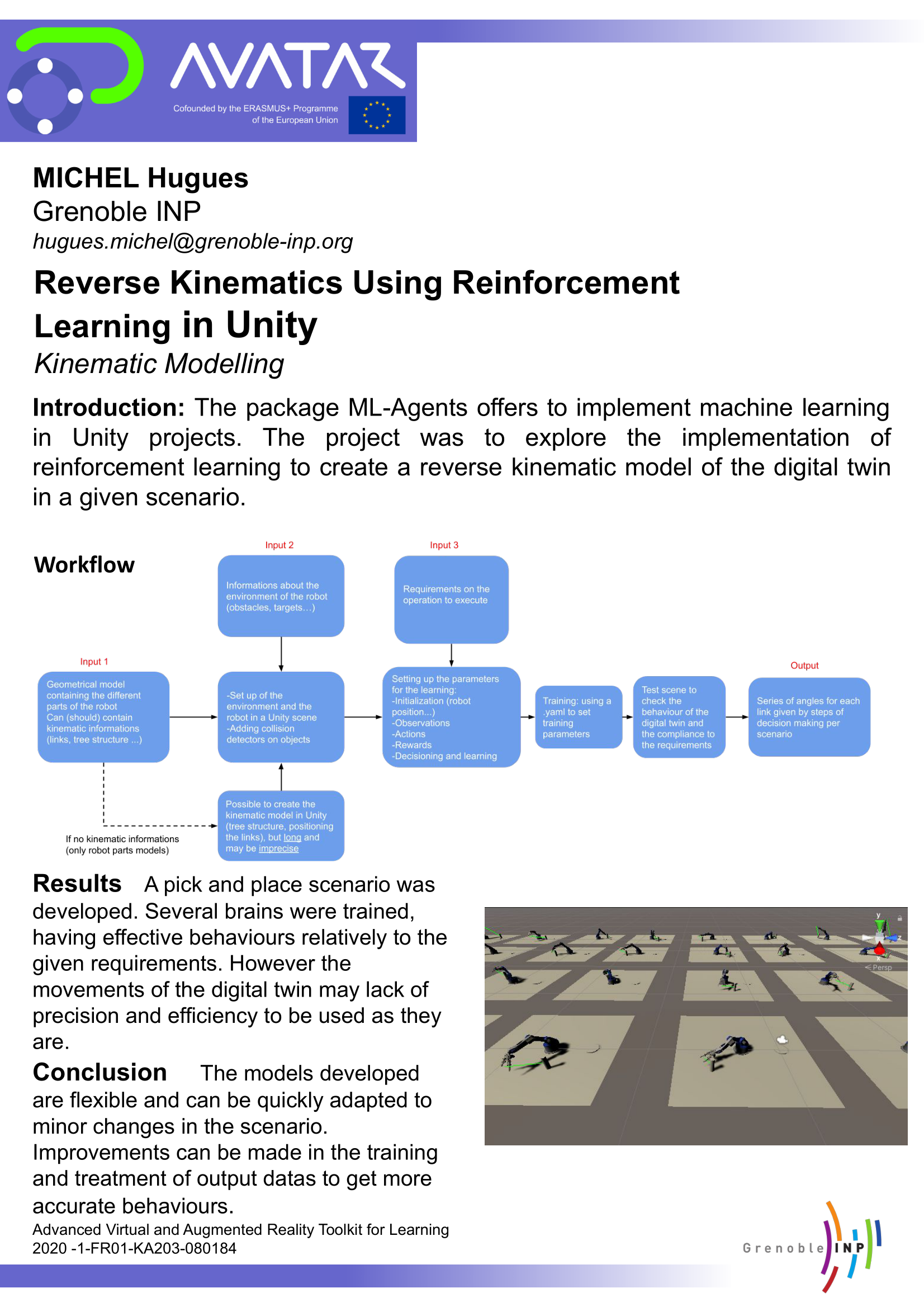
Using Reinforcement Learning to simulate robot Inverse Kinematics in Unity
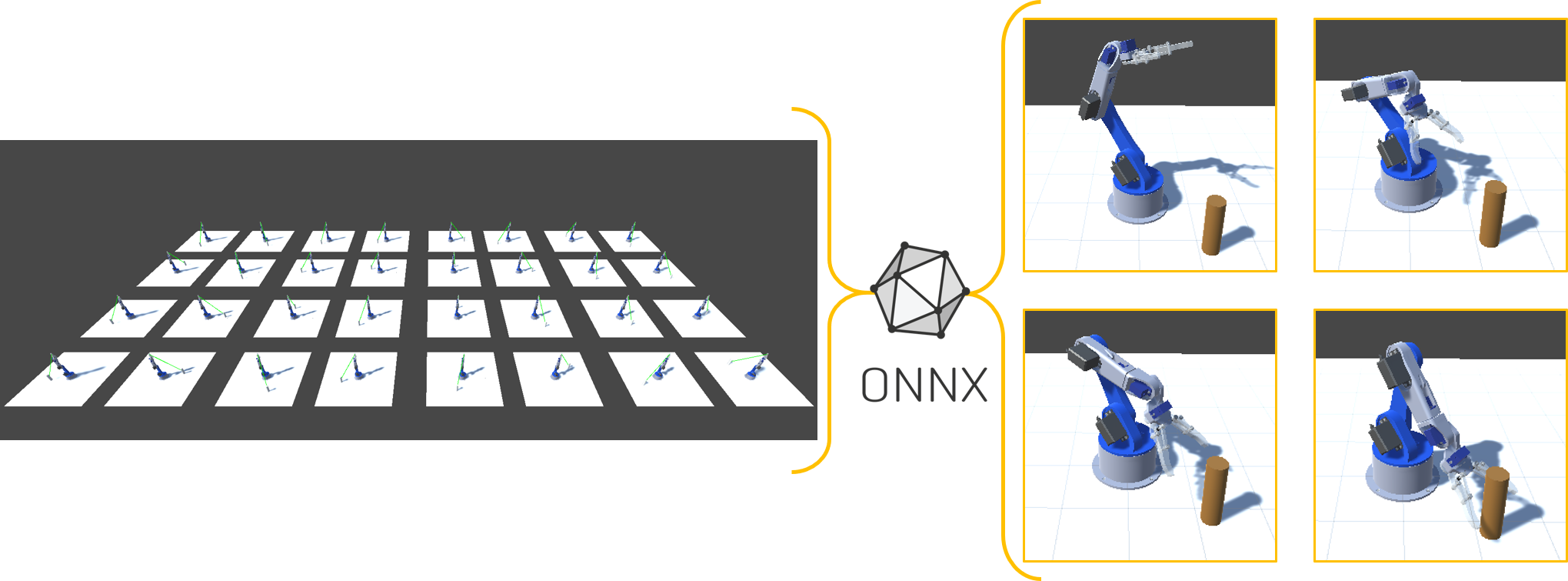
Process to develop a reverse kinematic model of a robot arm in given scenarios using reinforcement learning in Unity with the ML-Agents package. The ML training environment for this task is to move the robot arm to reach the target object from any state. The arm must not go below the ground and the robot must not collide with its own parts.
Poster
Workflow development
| INPUTS: Geometrical model of the robot (links, tree structure, etc) - Environment assets (obstacles, targets…) - Requirements on the operation to execute |  | OUTPUT: .onnx brain able to create a trajectory to reach a given target |
Workflow building-blocks
| Acitivities | Overview |
|---|---|
| A1 Environment set up | • Description: Add all the assets that are included in the scene. For the robot, define its structure, the relationship between the different axes and the limits of movement. Additionally, define the position and orientation of the objects in the Unity scene, and ensure that each physical object has a collider or Rigidbody to register collisions. In case of using methods like OnTriggerEnter for collision detection, it is necessary to check isTrigger. • Input: 3D Assets (Robot arm, pick object, etc) • Output: Pick and place scenario • Control: Robot behavior • Resource: 3D CAD Model, URDF File |
| A2 Agent set up | • Description: For this task the robot has two objectives: 1) Avoid collision with the ground and with its own parts. 2) Reach the target object. To achieve this it is necessary to set the learning parameters: - Initialization: select the robot and add the BehaviorParameters and DecisionRequester component. Set the maximum number of steps per episode depending on the complexity of the task to be performed by the agent. - Observations: Create the episodes and at the beginning of each episode place the robot and the target in random positions within a reachable area for the robot. The observations should provide the agent with the necessary information to make informed decisions. This includes the current position and orientation of the robot, the location of the target, among others. These observations are added using the AddObservation() method within the CollectObservations() method. - Actions: Define the actions that can be performed by the agent. In this case, it is only a rotation of the robot’s axes to reach a given goal. The actions are specified in the OnActionReceived() method.- Rewards: Build the reward system for the agent, this is crucial to drive the agent’s learning, as it allows to verify if the agent is doing something wanted or not. Within the OnActionReceived() method, after processing the actions, a reward or penalty should be provided using AddReward() or SetReward(). A positive reward should be given when the robot performs desirable actions (e.g., moving towards the target), while penalties (negative rewards) should be used when the robot performs undesirable actions (e.g., moving away from the target or exceeding movement limits). Decisions and Learning: Configure how and when the agent will make decisions. In the Decision Requester script the decision period is set. This value represents how many simulation steps must be taken before the agent requests a new action. A higher value will allow the agent to learn the consequences of an action for a longer time before requesting the next action. • Input: ML-Agents release 12 • Output: Agent set up and C# Scripts • Control: Behavioral expectation • Resource: Unity 3D, ML Documentation, Visual Studio |
| A3 Training | • Description: The training process with ML-Agents in Unity starts with the configuration of the trainer_config.yaml file. Here are defined the type of trainer, hyperparameters such as batch size, buffer size, learning rate, and the neural network configuration, including the number of hidden units and layers. Before starting the training, a “robot farm” is created, which is basically a scene with multiple agents. This allows the learning process to be accelerated.To start training, it is necessary to have the ML-Agents Python server installed and activated. This server communicates with Unity to facilitate the training process. During this training process, it is likely that erratic movements of the robot will be observed, but over time, these movements should improve. It is possible to monitor the process through TensorBoard. • Input: trainer_config.yam file, Robot farm and Pyhon Server • Output: Robot behavior • Control: Parameter settings • Resource: TensorBoard, Unity 3D |
| A4 Results of training | • Description: Once the training is completed, the trained neural network model will be saved and ready to be used. A brain folder is created within the results folder in the Unity project directory. Inside the folder is the .onnx file which can be easily dragged and dropped into the Model field of the Behavioral Parameters component of the robot. Additionally, the inference mode must be selected to activate the brain and enable the agent to execute tasks based on its acquired knowledge. • Input: Training results • Output: .onnx brain able to create a trajectory to reach a given target • Control: Achievement of the task, i.e. the robot is able to reach a given target object • Resource: Unity 3D, PyTotch, Visual Studio |
Results
A pick and place scenario was developed. Several brains were trained, having effective behaviours relatively to the given requirements. However the movements of the digital twin may lack of precision and efficiency to be used as they are.
Conclusion
The models developed are flexible and can be quickly adapted to minor changes in the scenario. Improvements can be made in the training and treatment of output datas to get more accurate behaviours.
Avatar for me
This project is an amazing way to explore a subject and have the possibility to exchange with international students about the details of our works. Furthermore, I love the idea of developping knowledges that can be useful to other students in the future.
References
- General documentation
- Installation
- Getting started guide Part1
- Getting started guide Part1
- Explanation of the parameters in the config file